
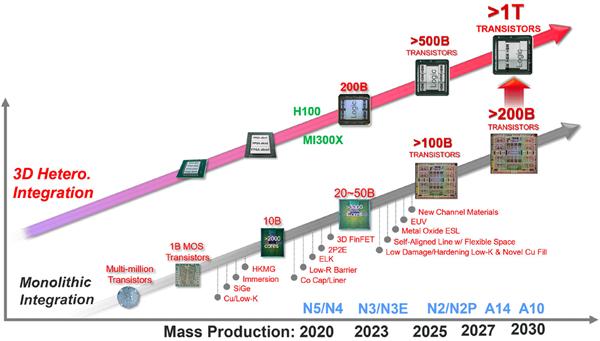





8 月 27 日消息,在近日盛大召开的 Hot Chips 2024 大会上,美国 AI 芯片初创公司 SambaNova 惊艳亮相,首次全面且详细地介绍了其具有重大突破意义的全球首款面向万亿参数规模的人工智能(AI)模型的 AI 芯片系统 —— 基于可重构数据流单元 (RDU) 的 AI 芯片 SN40L。

据深入介绍,基于 SambaNova 的 SN40L 的 8 芯片系统展现出了令人瞩目的强大性能。它能够为 5 万亿参数模型提供有力支撑,单个系统节点上的序列长度可达 256k+。在与行业巨头英伟达的 H100 芯片进行对比时,SN40L 表现极为出色。不仅推理性能达到了 H100 的 3.1 倍,在训练性能方面也高达 H100 的 2 倍,而总拥有成本更是仅有英伟达 H100 的十分之一。
SambaNova SN40L 基于台积电 5nm 制程工艺精心打造,拥有高达 1020 亿个晶体管,相比之下,英伟达 H100 为 800 亿个晶体管。SN40L 还拥有 1040 个自研的 “Cerulean” 架构的 RDU 计算核心,整体算力达 638TFLOPS(BF16)。虽然单纯从算力数值上看不算特别突出,但是 SN40L 的关键优势在于其拥有三层数据流存储器。其中包括 520MB 的片上 SRAM 内存,这一内存容量远远高于此前 Groq 推出的号称推理速度是英伟达 GPU 的 10 倍、功耗仅为其十分之一的 LPU 所集成的 230MB SRAM。此外,SN40L 还集成了 64GB 的 HBM 内存以及 1.5TB 的外部大容量内存,这使得它能够轻松应对万亿参数规模的大模型的训练和推理。
SambaNova 在推出基于 8 个 SN40L 芯片系统的同时,还推出了 16 个芯片的系统。这一系统将可获得 8GB 片内 SRAM、1TB HBM 和 24TB 外部 DDR 内存,使得片上 SRAM 和集成的 HBM 内存之间的带宽高达 25.5TB/s,HBM 和外部 DDR 内存之间的带宽可达 1600GB/s。如此高的带宽带来了显著的低延时优势,比如运行 Llama 3.1 8B 模型,延时低于 0.01s。
据 SambaNova 介绍,基于 8 个 SN40L 芯片的标准 AI 服务器系统在运行 80 亿参数的 AI 大模型时,速度达到了基于 8 张英伟达 H100 加速卡的 DGX H100 系统的 3.7 倍(每生成 20 个 Token 所耗费的时间),而整个系统所占用的空间也只有 DGX H100 的 1/19,模型切换时间也仅有 DGX H100 系统的 1/15。
在芯片推理性能和训练性能方面,SN40L 分别达到了英伟达 H100 的 3.1 倍和 2 倍。
亿配芯城(ICgoodFind)认为,SambaNova 推出的 SN40L 芯片在 AI 领域展现出了强大的竞争力和创新力。其优秀的性能和独特的设计为 AI 芯片的发展带来了新的方向和可能性。亿配芯城(ICgoodFind)将持续关注 AI 芯片领域的技术进步,为客户提供更优质的芯片产品和服务,助力 AI 产业的蓬勃发展。





















